Calculating Covariance with Python and Numpy
Question:
I am trying to figure out how to calculate covariance with the Python Numpy function cov. When I pass it two one-dimentional arrays, I get back a 2×2 matrix of results. I don’t know what to do with that. I’m not great at statistics, but I believe covariance in such a situation should be a single number. This is what I am looking for. I wrote my own:
def cov(a, b):
if len(a) != len(b):
return
a_mean = np.mean(a)
b_mean = np.mean(b)
sum = 0
for i in range(0, len(a)):
sum += ((a[i] - a_mean) * (b[i] - b_mean))
return sum/(len(a)-1)
That works, but I figure the Numpy version is much more efficient, if I could figure out how to use it.
Does anybody know how to make the Numpy cov function perform like the one I wrote?
Thanks,
Dave
Answers:
When a and b are 1-dimensional sequences, numpy.cov(a,b)[0][1] is equivalent to your cov(a,b).
The 2×2 array returned by np.cov(a,b) has elements equal to
cov(a,a) cov(a,b)
cov(a,b) cov(b,b)
(where, again, cov is the function you defined above.)
Thanks to unutbu for the explanation. By default numpy.cov calculates the sample covariance. To obtain the population covariance you can specify normalisation by the total N samples like this:
numpy.cov(a, b, bias=True)[0][1]
or like this:
numpy.cov(a, b, ddof=0)[0][1]
Note that starting in Python 3.10, one can obtain the covariance directly from the standard library.
Using statistics.covariance which is a measure (the number you’re looking for) of the joint variability of two inputs:
from statistics import covariance
# x = [1, 2, 3, 4, 5, 6, 7, 8, 9]
# y = [1, 2, 3, 1, 2, 3, 1, 2, 3]
covariance(x, y)
# 0.75
I am trying to figure out how to calculate covariance with the Python Numpy function cov. When I pass it two one-dimentional arrays, I get back a 2×2 matrix of results. I don’t know what to do with that. I’m not great at statistics, but I believe covariance in such a situation should be a single number. This is what I am looking for. I wrote my own:
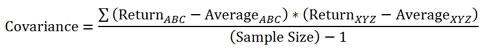{kind=link}
def cov(a, b):
if len(a) != len(b):
return
a_mean = np.mean(a)
b_mean = np.mean(b)
sum = 0
for i in range(0, len(a)):
sum += ((a[i] - a_mean) * (b[i] - b_mean))
return sum/(len(a)-1)
That works, but I figure the Numpy version is much more efficient, if I could figure out how to use it.
Does anybody know how to make the Numpy cov function perform like the one I wrote?
Thanks,
Dave
When a and b are 1-dimensional sequences, numpy.cov(a,b)[0][1] is equivalent to your cov(a,b).
The 2×2 array returned by np.cov(a,b) has elements equal to
cov(a,a) cov(a,b)
cov(a,b) cov(b,b)
(where, again, cov is the function you defined above.)
Thanks to unutbu for the explanation. By default numpy.cov calculates the sample covariance. To obtain the population covariance you can specify normalisation by the total N samples like this:
numpy.cov(a, b, bias=True)[0][1]
or like this:
numpy.cov(a, b, ddof=0)[0][1]
Note that starting in Python 3.10, one can obtain the covariance directly from the standard library.
Using statistics.covariance which is a measure (the number you’re looking for) of the joint variability of two inputs:
from statistics import covariance
# x = [1, 2, 3, 4, 5, 6, 7, 8, 9]
# y = [1, 2, 3, 1, 2, 3, 1, 2, 3]
covariance(x, y)
# 0.75