Getting the r-squared value using curve_fit
Question:
I am a beginner with both Python and all its libs. But I have managed to make a small program that works as intended.
It takes a string, counts the occurence of the different letters and plots them in a graph and then applies a equation and its curve.¨
Now i would like to get the r-squared value of the fit.
The overall idea is to compare different kinds of text from articles on different levels and see how strong the overall pattern is.
Is just an excersise and I am new, so a easy to understand answer would be awesome.
The code is:
import numpy as np
import math
import matplotlib.pyplot as plt
from matplotlib.pylab import figure, show
from scipy.optimize import curve_fit
s="""det, og deres undersøgelse af hvor meget det bliver brugt viser, at der kun er seks plugins, som benyttes af mere end 5 % af Chrome-brugere.
Problemet med teknologien er, at den ivivuilv rduyd iytf ouyf ouy yg oyuf yd iyt erzypu zhrpyh dfgopaehr poargi ah pargoh ertao gehorg aeophgrpaoghraprbpaenbtibaeriber en af hovedårsagerne til sikkerhedshuller, ustabilitet og deciderede nedbrud af browseren.
Der vil ikke bve lukket for API'et ivivuilv rduyd iytf ouyf ouy yg oyuf yd iyt erzypu zhrpyh dfgopaehr poargi ah pargoh ertao gehorg aeophgrpaoghraprbpaenbtibaeriber en af hovedårsagerne til sikkerhedshuller, ustabilitet og deciderede nedbrud af browseren.
Der vil ikke blive lukket for API'et på én gang, men det vil blive udfaset i løbet af et års tid. De mest populære plugins får lov at fungere i udfasningsperioden; Det drejer sig om: Silverlight (anvendt af 15 % af Chrome-brugere sidste måned), Unity (9,1 %), Google Earth (9,1 %), Java (8,9%), Google Talk (8,7 %) og Facebook Video (6,0 %).
Det er muligt at hvidliste andre plugins, men i slutningen af 2014 forventer udviklerne helt at lukke for brugen af dem."""
fordel=[]
alf=['a','b','c','d','e','f','g','h','i','j','k','l','m','n','o','p','q','r','s','t','u','v','w','x','y','z','æ','ø','å']
i=1
p=0
fig = figure()
ax1 = fig.add_subplot(1,2,0)
for i in range(len(alf)):
fordel.append(s.count(alf[i]))
i=i+1
fordel=sorted(fordel,key=int,reverse=True)
yFit=fordel
xFit=[0,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28]
def func(x, a, b):
return a * (b ** x)
popt, pcov = curve_fit(func, xFit, yFit)
t = np.arange(0.0, 30.0, 0.1)
a=popt[0]
b=popt[1]
s = (a*b**t)
ax1.plot(t,s)
print(popt)
yMax=math.ceil(fordel[0]+5)
ax1.axis([0,30,0,yMax])
for i in range(0,int(len(alf))*2,2):
fordel.insert(i,p)
p=p+1
for i in range(0,int(len(fordel)/2)):
ax1.scatter(fordel[0],fordel[1])
fordel.pop(0)
fordel.pop(0)
plt.show()
show()
Answers:
Computing 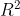 :
:
The value can be found using the mean (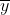 ), the total sum of squares (
), the total sum of squares (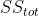 ), and the residual sum of squares (
), and the residual sum of squares (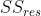 ). Each is defined as:
). Each is defined as:
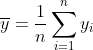
%5E2)
%5E2)
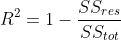
where 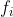 is the function value at point
is the function value at point 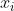 . Taken from Wikipedia.
. Taken from Wikipedia.
From scipy.optimize.curve_fit():
-
You can get the parameters (popt) from curve_fit() with
popt, pcov = curve_fit(f, xdata, ydata)
-
You can get the residual sum of squares () with
residuals = ydata- f(xdata, *popt)ss_res = numpy.sum(residuals**2)
-
You can get the total sum of squares () with
ss_tot = numpy.sum((ydata-numpy.mean(ydata))**2)
-
And finally, the -value with,
r_squared = 1 - (ss_res / ss_tot)
I think this method is an easier way to solve the minimize problem:
res = minimize(func) # your optimize function
cof = np.reshape(np.array(res.x),(-1,1))
r_square = 1.0 - (np.var(ydata-xdata.dot(cof)) / np.var(ydata))
# or
# r_square = 1 - np.square(ydata-xdata.dot(cof)).sum() / (np.var(ydata) * len(ydata))
There seems to be some background about R2 not being implemented directly in scipy.
You can use sklearn.metrics.r2_score.
From your example:
from sklearn.metrics import r2_score
popt, pcov = curve_fit(func, xFit, yFit)
y_pred = func(xFit, *popt)
r2_score(yFit, y_pred)
I am a beginner with both Python and all its libs. But I have managed to make a small program that works as intended.
It takes a string, counts the occurence of the different letters and plots them in a graph and then applies a equation and its curve.¨
Now i would like to get the r-squared value of the fit.
The overall idea is to compare different kinds of text from articles on different levels and see how strong the overall pattern is.
Is just an excersise and I am new, so a easy to understand answer would be awesome.
The code is:
import numpy as np
import math
import matplotlib.pyplot as plt
from matplotlib.pylab import figure, show
from scipy.optimize import curve_fit
s="""det, og deres undersøgelse af hvor meget det bliver brugt viser, at der kun er seks plugins, som benyttes af mere end 5 % af Chrome-brugere.
Problemet med teknologien er, at den ivivuilv rduyd iytf ouyf ouy yg oyuf yd iyt erzypu zhrpyh dfgopaehr poargi ah pargoh ertao gehorg aeophgrpaoghraprbpaenbtibaeriber en af hovedårsagerne til sikkerhedshuller, ustabilitet og deciderede nedbrud af browseren.
Der vil ikke bve lukket for API'et ivivuilv rduyd iytf ouyf ouy yg oyuf yd iyt erzypu zhrpyh dfgopaehr poargi ah pargoh ertao gehorg aeophgrpaoghraprbpaenbtibaeriber en af hovedårsagerne til sikkerhedshuller, ustabilitet og deciderede nedbrud af browseren.
Der vil ikke blive lukket for API'et på én gang, men det vil blive udfaset i løbet af et års tid. De mest populære plugins får lov at fungere i udfasningsperioden; Det drejer sig om: Silverlight (anvendt af 15 % af Chrome-brugere sidste måned), Unity (9,1 %), Google Earth (9,1 %), Java (8,9%), Google Talk (8,7 %) og Facebook Video (6,0 %).
Det er muligt at hvidliste andre plugins, men i slutningen af 2014 forventer udviklerne helt at lukke for brugen af dem."""
fordel=[]
alf=['a','b','c','d','e','f','g','h','i','j','k','l','m','n','o','p','q','r','s','t','u','v','w','x','y','z','æ','ø','å']
i=1
p=0
fig = figure()
ax1 = fig.add_subplot(1,2,0)
for i in range(len(alf)):
fordel.append(s.count(alf[i]))
i=i+1
fordel=sorted(fordel,key=int,reverse=True)
yFit=fordel
xFit=[0,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28]
def func(x, a, b):
return a * (b ** x)
popt, pcov = curve_fit(func, xFit, yFit)
t = np.arange(0.0, 30.0, 0.1)
a=popt[0]
b=popt[1]
s = (a*b**t)
ax1.plot(t,s)
print(popt)
yMax=math.ceil(fordel[0]+5)
ax1.axis([0,30,0,yMax])
for i in range(0,int(len(alf))*2,2):
fordel.insert(i,p)
p=p+1
for i in range(0,int(len(fordel)/2)):
ax1.scatter(fordel[0],fordel[1])
fordel.pop(0)
fordel.pop(0)
plt.show()
show()
Computing :
The value can be found using the mean (
), the total sum of squares (
), and the residual sum of squares (
). Each is defined as:
where is the function value at point
. Taken from Wikipedia.
From scipy.optimize.curve_fit():
-
You can get the parameters (
popt) fromcurve_fit()withpopt, pcov = curve_fit(f, xdata, ydata) -
You can get the residual sum of squares (
residuals = ydata- f(xdata, *popt)ss_res = numpy.sum(residuals**2)
-
You can get the total sum of squares (
ss_tot = numpy.sum((ydata-numpy.mean(ydata))**2) -
And finally, the
r_squared = 1 - (ss_res / ss_tot)
I think this method is an easier way to solve the minimize problem:
res = minimize(func) # your optimize function
cof = np.reshape(np.array(res.x),(-1,1))
r_square = 1.0 - (np.var(ydata-xdata.dot(cof)) / np.var(ydata))
# or
# r_square = 1 - np.square(ydata-xdata.dot(cof)).sum() / (np.var(ydata) * len(ydata))
There seems to be some background about R2 not being implemented directly in scipy.
You can use sklearn.metrics.r2_score.
From your example:
from sklearn.metrics import r2_score
popt, pcov = curve_fit(func, xFit, yFit)
y_pred = func(xFit, *popt)
r2_score(yFit, y_pred)