Select features by importance for clustering
Question:
So I train a normal Random Forest in Scikit-Learn:
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import make_classification
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.4)
clf_rf = RandomForestClassifier(max_depth=4, random_state=42)
clf_rf.fit(X_train, y_train)
print(classification_report(y_test, clf_rf.predict(X_test)))
Now I want to do t-SNE but only with n (e.g. 10) most important values regarding Random Forest Classifier. How to approach? Below is my code for t-SNE but using all features (X). X is a pandas dataframe.
from sklearn.manifold import TSNE
tsne = TSNE(n_components=2, random_state=11)
X_2d = tsne.fit_transform(X)
target_ids = range(0,2)
target_names = np.array(["label 1", "label 2"])
plt.figure(figsize=(6, 5))
colors = 'r', 'g'
for i, c, label in zip(target_ids, colors, target_names):
plt.scatter(X_2d[y == i, 0], X_2d[y == i, 1], c=c, label=label)
plt.legend()
plt.xlabel("Dimension 1")
plt.ylabel("Dimension 2")
plt.show()
Answers:
import pandas as pd
feature_names = [f'feature {i}' for i in range(X_train.shape[1])]
def get_feature_importance(model):
importances = forest.feature_importances_
std = np.std([
tree.feature_importances_ for tree in forest.estimators_], axis=0)
elapsed_time = time.time() - start_time
print(f"Elapsed time to compute the importances: "
f"{elapsed_time:.3f} seconds")
return imporatnces
importances = get_feature_importance(clf_rf) # get important features to randomforest classifier
forest_importances = pd.Series(importances, index=feature_names) # convert to dataframe
# Let’s plot the impurity-based importance.
fig, ax = plt.subplots()
forest_importances.plot.bar(yerr=std, ax=ax)
ax.set_title("Feature importances using MDI")
ax.set_ylabel("Mean decrease in impurity")
fig.tight_layout()
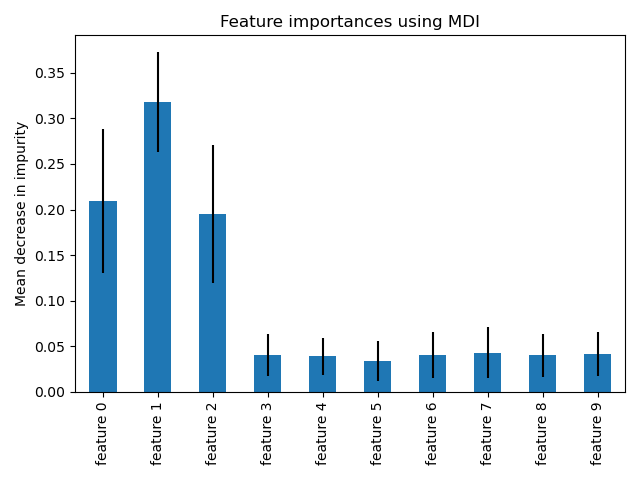
[1] – sklearn docs – extracting feature importance from random classifier
You could use SelectFromModel to extract the most important features:
import numpy as np
from sklearn.datasets import make_classification
from sklearn.ensemble import RandomForestClassifier
from sklearn.feature_selection import SelectFromModel
# generate the data
X, y = make_classification(random_state=42)
print(X.shape)
# (100, 20)
# fit the model
clf = RandomForestClassifier(max_depth=4, random_state=42)
clf.fit(X, y)
# extract the most important features
selector = SelectFromModel(estimator=clf, max_features=10, threshold=-np.inf, prefit=True)
X_ = selector.transform(X)
print(X_.shape)
# (100, 10)
So I train a normal Random Forest in Scikit-Learn:
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import make_classification
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.4)
clf_rf = RandomForestClassifier(max_depth=4, random_state=42)
clf_rf.fit(X_train, y_train)
print(classification_report(y_test, clf_rf.predict(X_test)))
Now I want to do t-SNE but only with n (e.g. 10) most important values regarding Random Forest Classifier. How to approach? Below is my code for t-SNE but using all features (X). X is a pandas dataframe.
from sklearn.manifold import TSNE
tsne = TSNE(n_components=2, random_state=11)
X_2d = tsne.fit_transform(X)
target_ids = range(0,2)
target_names = np.array(["label 1", "label 2"])
plt.figure(figsize=(6, 5))
colors = 'r', 'g'
for i, c, label in zip(target_ids, colors, target_names):
plt.scatter(X_2d[y == i, 0], X_2d[y == i, 1], c=c, label=label)
plt.legend()
plt.xlabel("Dimension 1")
plt.ylabel("Dimension 2")
plt.show()
import pandas as pd
feature_names = [f'feature {i}' for i in range(X_train.shape[1])]
def get_feature_importance(model):
importances = forest.feature_importances_
std = np.std([
tree.feature_importances_ for tree in forest.estimators_], axis=0)
elapsed_time = time.time() - start_time
print(f"Elapsed time to compute the importances: "
f"{elapsed_time:.3f} seconds")
return imporatnces
importances = get_feature_importance(clf_rf) # get important features to randomforest classifier
forest_importances = pd.Series(importances, index=feature_names) # convert to dataframe
# Let’s plot the impurity-based importance.
fig, ax = plt.subplots()
forest_importances.plot.bar(yerr=std, ax=ax)
ax.set_title("Feature importances using MDI")
ax.set_ylabel("Mean decrease in impurity")
fig.tight_layout()
[1] – sklearn docs – extracting feature importance from random classifier
You could use SelectFromModel to extract the most important features:
import numpy as np
from sklearn.datasets import make_classification
from sklearn.ensemble import RandomForestClassifier
from sklearn.feature_selection import SelectFromModel
# generate the data
X, y = make_classification(random_state=42)
print(X.shape)
# (100, 20)
# fit the model
clf = RandomForestClassifier(max_depth=4, random_state=42)
clf.fit(X, y)
# extract the most important features
selector = SelectFromModel(estimator=clf, max_features=10, threshold=-np.inf, prefit=True)
X_ = selector.transform(X)
print(X_.shape)
# (100, 10)