Python transform data long to wide
Question:
I’m looking to transform some data in Python.
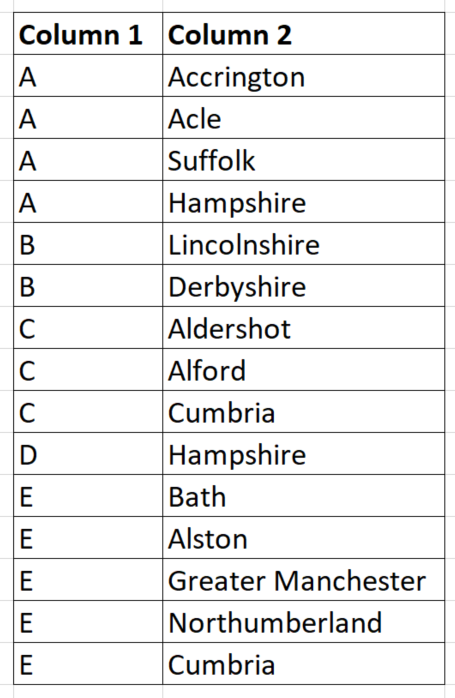
Originally, in column 1 there are various identifiers (A to E in this example) associated with towns in column 2. There is a separate row for each identifier and town association. There can be any number of identifier to town associations.
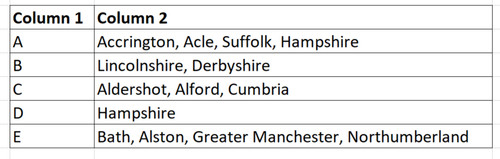
I’d like to end up with ONE row per identifier and with all the associated towns going horizontally separated by commas.
Tried using long to wide but having difficulty in doing the above, appreciate any suggestions.
Thank you
Answers:
One way to do it is using gruopby. For example, you can group by Column 1 and apply a function that returns the list of unique values for each group (i.e. each code).
import numpy as np
import pandas as pd
df = pd.DataFrame({
'col1': 'A A A A B B C C C D E E E E E'.split(' '),
'col2': ['Accrington', 'Acle', 'Suffolk', 'Hampshire', 'Lincolnshire',
'Derbyshire', 'Aldershot', 'Alford', 'Cumbria', 'Hampshire', 'Bath',
'Alston', 'Greater Manchester', 'Northumberland', 'Cumbria'],
})
def get_towns(town_list):
return ', '.join(np.unique(town_list))
df.groupby('col1')['col2'].apply(get_towns)
And the result is:
col1
A Accrington, Acle, Hampshire, Suffolk
B Derbyshire, Lincolnshire
C Aldershot, Alford, Cumbria
D Hampshire
E Alston, Bath, Cumbria, Greater Manchester, Nor...
Name: col2, dtype: object
Note: the last line contains also Cumbria, differently from you expected results as this value appears also with the code E. I guess that was a typo in your question…
Another option is to use .groupby with aggregate because conceptually, this is not a pivoting operation but, well, an aggregation (concatenation) of values. This solution is quite similar to Luca Clissa’s answer, but it uses the pandas api instead of numpy.
>>> df.groupby("col1").col2.agg(list)
col1
A [Accrington, Acle, Suffolk, Hampshire]
B [Lincolnshire, Derbyshire]
C [Aldershot, Alford, Cumbria]
D [Hampshire]
E [Bath, Alston, Greater Manchester, Northumberl...
Name: col2, dtype: object
That gives you cells of lists; if you need strings, add a .str.join(", "):
>>> df.groupby("col1").col2.agg(list).str.join(", ")
col1
A Accrington, Acle, Suffolk, Hampshire
B Lincolnshire, Derbyshire
C Aldershot, Alford, Cumbria
D Hampshire
E Bath, Alston, Greater Manchester, Northumberla...
Name: col2, dtype: object
If you want col1 as a normal column instead of an index, add a .reset_index() at the end.
I’m looking to transform some data in Python.
Originally, in column 1 there are various identifiers (A to E in this example) associated with towns in column 2. There is a separate row for each identifier and town association. There can be any number of identifier to town associations.
I’d like to end up with ONE row per identifier and with all the associated towns going horizontally separated by commas.
Tried using long to wide but having difficulty in doing the above, appreciate any suggestions.
Thank you
One way to do it is using gruopby. For example, you can group by Column 1 and apply a function that returns the list of unique values for each group (i.e. each code).
import numpy as np
import pandas as pd
df = pd.DataFrame({
'col1': 'A A A A B B C C C D E E E E E'.split(' '),
'col2': ['Accrington', 'Acle', 'Suffolk', 'Hampshire', 'Lincolnshire',
'Derbyshire', 'Aldershot', 'Alford', 'Cumbria', 'Hampshire', 'Bath',
'Alston', 'Greater Manchester', 'Northumberland', 'Cumbria'],
})
def get_towns(town_list):
return ', '.join(np.unique(town_list))
df.groupby('col1')['col2'].apply(get_towns)
And the result is:
col1
A Accrington, Acle, Hampshire, Suffolk
B Derbyshire, Lincolnshire
C Aldershot, Alford, Cumbria
D Hampshire
E Alston, Bath, Cumbria, Greater Manchester, Nor...
Name: col2, dtype: object
Note: the last line contains also Cumbria, differently from you expected results as this value appears also with the code E. I guess that was a typo in your question…
Another option is to use .groupby with aggregate because conceptually, this is not a pivoting operation but, well, an aggregation (concatenation) of values. This solution is quite similar to Luca Clissa’s answer, but it uses the pandas api instead of numpy.
>>> df.groupby("col1").col2.agg(list)
col1
A [Accrington, Acle, Suffolk, Hampshire]
B [Lincolnshire, Derbyshire]
C [Aldershot, Alford, Cumbria]
D [Hampshire]
E [Bath, Alston, Greater Manchester, Northumberl...
Name: col2, dtype: object
That gives you cells of lists; if you need strings, add a .str.join(", "):
>>> df.groupby("col1").col2.agg(list).str.join(", ")
col1
A Accrington, Acle, Suffolk, Hampshire
B Lincolnshire, Derbyshire
C Aldershot, Alford, Cumbria
D Hampshire
E Bath, Alston, Greater Manchester, Northumberla...
Name: col2, dtype: object
If you want col1 as a normal column instead of an index, add a .reset_index() at the end.